

In the last post, Building the synthetic CPU, I expected the CPU, running a machine code version of the Mandelbrot test, to run at least 10x faster.
Well, here’s the test:
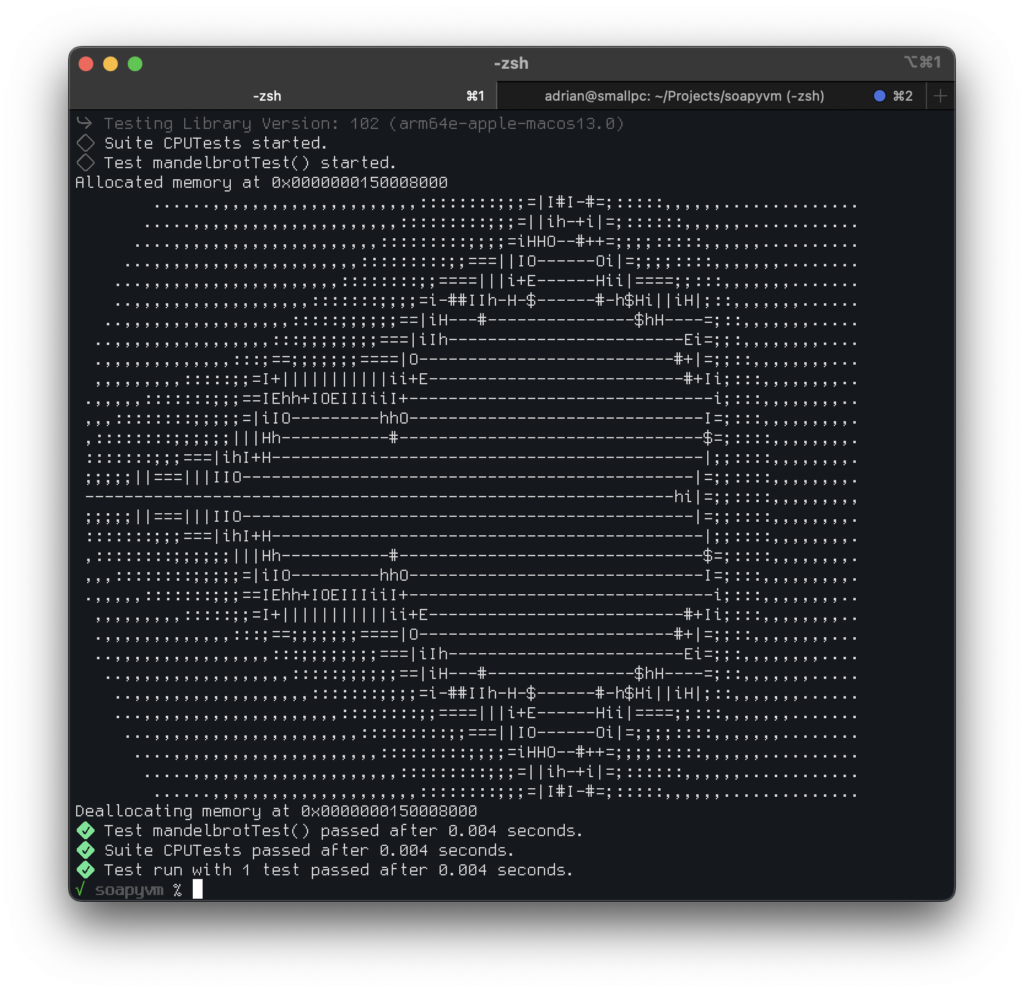
It ran in 4ms, and the original, SoapyBASIC interpreted version runs in about 50ms.
So I’m happy with that.
My synthetic CPU does an iterative decode of the instruction from memory and execute in one pass, so there’s no parallel decode/execute and no caching of decoded instructions.
I tried decoding instructions and producing closures (this is in Swift) that execute in a chain, but the overheads made it quite slow.
If I choose to move this to C that’s what I’d do though; a kind of pseudo-JIT.
That’s all for this post. The next steps are completing the last 15% or so instructions not handled and writing a mini assembler (the Mandelbrot code producing the above was hand assembled 🙁 ).
Below is that assembly code. As you can see it’s a bit ARM/RISC-V like and although there is no memory access in here, it is a load/store architecture and every instruction is 32-bits. 32 each of general purpose and floating point registers.
More on this in future articles.
fset fs0, 79.0 ; num lines
fset fs1, 30.0 ; num cols
set s0, 16 ; max iter
fset fs2, -2.0 ; minRe
fset fs3, 1.0 ; maxRe
fset fs4, -1.0 ; minIm
fset fs5, 1.0 ; maxIm
; fs6 (imstep) = (maxIm-minIm)/lines
fsub fs6, fs5, fs4
fdiv fs6, fs6, fs0
; fs7 (restep) = (maxRe-minRe)/cols
fsub fs7, fs3, fs2
fdiv fs7, fs7, fs1
; for im(fs8) = minIm to maxIm step imstep
fcopy fs8, fs4
imloop:
; for re(fs9) = minRe to maxRe step restep
fcopy fs9, fs2
reloop:
fcopy fs10, fs9 ; zr(fs10)=re
fcopy fs11, fs8 ; zi(fs11)=im
; while n (s1) < maxIter
set s1, 0
nloop:
sub zero, s1, s0 ; zero = n-maxIter
; above could be cmp s1, s0 pseudo-instruction?
b_eq nbreak
; a(fs12)=zr*zr, b(fs13)=zi*zi
fmul fs12, fs10, fs10
fmul fs13, fs11, fs11
; if a+b > 4 break
fadd ft0, fs12, fs13
fset ft1, 4.0
fcmp ft0, ft1
b_gt nbreak
; zi = 2*zr*zi+im
fset ft0, 2.0
fmul ft0, fs10, ft0
fmul ft0, fs11, ft0
fadd fs11, ft0, fs8
; zr = a-b+re
fsub ft0, fs12, fs13
fadd fs10, ft0, fs9
; next n
add s1, s1, 1
b nloop
nbreak:
; print char n
copy a0, s1 a0=n
syscall 2
; next re(fs9)
fadd fs9, fs9, fs7
fcmp fs9, fs3 ; re,maxRe
b_le reloop
; print new line
set a0, 10
syscall 1
; next im(fs8)
fadd fs8, fs8, fs7
fcmp fs8, fs5 ; im,maxIm
b_le imloop
halt
Leave a Reply